
With Automated ETL pipeline at the forefront, this paragraph opens a window to an amazing start and intrigue, inviting readers to embark on a storytelling ahrefs author style filled with unexpected twists and insights.
Automated ETL pipeline revolutionizes data processing, offering a seamless solution to streamline complex ETL processes efficiently and accurately. Dive into the world of automated ETL pipelines and discover the key components, benefits, challenges, and best practices that shape this transformative technology.
When it comes to cloud data integration , businesses are constantly seeking efficient solutions to manage and analyze their data across multiple platforms. One crucial aspect of this process is the ETL process , which involves extracting, transforming, and loading data from various sources. To ensure seamless data flow, organizations rely on advanced data synchronization tools that can synchronize information in real-time.
Introduction to Automated ETL Pipeline
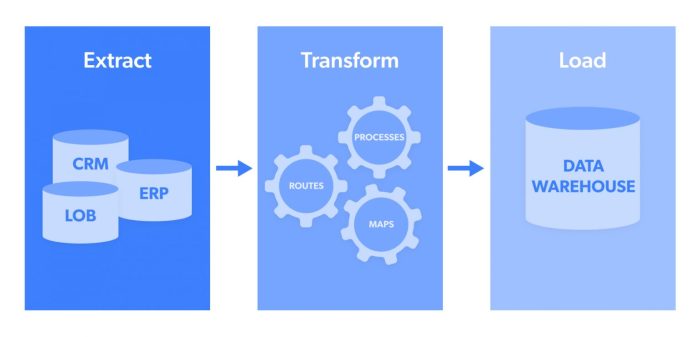
An ETL pipeline refers to a series of processes involved in Extracting, Transforming, and Loading data from various sources into a destination where it can be analyzed. Automation in ETL processes involves using technology to streamline and accelerate these tasks, reducing manual intervention and human error.
Components of an Automated ETL Pipeline
- Extraction: Involves retrieving data from different sources such as databases, applications, or files.
- Transformation: Includes cleaning, structuring, and preparing the data for analysis.
- Loading: Involves transferring the transformed data into a data warehouse or database for storage and further processing.
Technologies commonly used in automating ETL processes, Automated ETL pipeline
- Apache NiFi: An open-source data integration tool that provides a visual interface for designing ETL workflows.
- Talend: Offers a suite of tools for data integration, including ETL automation.
- Informatica: A popular ETL tool that allows for efficient data extraction, transformation, and loading.
Benefits of Using Automated ETL Pipelines

Automating ETL pipelines brings several advantages, such as increased efficiency and accuracy in data processing. By reducing manual errors, organizations can improve data quality and make better-informed decisions based on reliable information.
When it comes to cloud data integration , businesses need reliable solutions to seamlessly connect and manage data across various platforms. Implementing an effective ETL process is crucial for extracting, transforming, and loading data efficiently. In addition, utilizing advanced data synchronization tools can help ensure data consistency and accuracy in real-time.
Challenges in Implementing Automated ETL Pipelines

- Data Quality: Ensuring that the data being processed is accurate and consistent across different sources.
- Scalability: Adapting the automated ETL pipeline to handle large volumes of data without compromising performance.
Best Practices for Designing Automated ETL Pipelines

- Design for Scalability: Ensure that the automated ETL pipeline can accommodate future growth and increased data volumes.
- Monitor Performance: Regularly monitor the ETL pipeline’s performance to identify bottlenecks and optimize data processing.
- Version Control: Implement version control practices to track changes and ensure data integrity throughout the pipeline.
In conclusion, Automated ETL pipelines emerge as the game-changer in data integration, paving the way for enhanced efficiency, accuracy, and scalability. Embrace the power of automation and witness a new era of streamlined data processing.


{kind=link}